Vortex Wake Performance Enhancement
The vortex wake calculation involves \(O(N^2)\) floating point operations where \(N\) relates directly to the number of wake nodes and vortex elements used for representing the vortex wake and to compute the flow induction at the blade. This presents a computational problem that can slow down the simulation. To address this issue, it is possible to parallelise the computation, as the flow induction at each wake node is computed independently of other wake nodes. The user can select between two parallelisation options: a multithreading approach that uses multiple Central processing units (CPUs) and a Graphical Processing Unit (GPU).
Multithreading
CPUs have the following features to increase performance of computationally expensive calculations:
- Increased number of cores (Multicore)
- Widened SIMD registers (Vectorisation)
The vortex wake computational code has been updated for performance and appropriate compiler settings have been selected to take advantage of the aforementioned benefits in compute power. This allows the vortex wake calculations to attain a performance close to the peak theoretical performance of modern CPUs.
Open multi-processing (OpenMP) is an application programming interface used to define a series of threads within the calculation to perform operations in parallel. The vortex wake implementation in Bladed uses OpenMP and allows the user to use multiple CPU threads for the calculation. The number of threads used should not be greater than the number of CPU cores (including hyper-threaded cores) available on the hardware.
The code also takes advantage of vectorisation. An appropriate data layout and algorithm is implemented that can be vectorised by a vectorizing compiler. This enables multiple floating point operations and loading of contiguous data to occur simultaneously during the calculation.
Dispatch to GPU
The structure of induction calculations from a vortex wake is suited for application of a GPU due to the high number of similar but independent computations. The open standard OpenCL is a widely implemented framework to parallelize computations on graphics cards. Shifting the time consuming calculation of wake induction to the GPU allows for a significant speed up over the standard implementation as can be seen below.
Configuration file
The user can select the graphics card to be used by using a configuration file via the Bladed user interface. This is helpful when using machines that have multiple graphic cards, especially when spreading multiple simulations over different machines with different hardware components. This configuration file is to be located on the same absolute path on each computer and should name the preferred graphics card for the upcoming simulation.
This JSON file has a simple structure and should contain the name of a device. An example of such a file is given below:
{
"gpu_selection": {
"device_name": "NVIDIA T600 Laptop GPU"
}
}
If no such file is provided or the file format is incorrect or contains the name of a non-existing device a default behaviour is implemented by choosing the first possible GPU. The names of all available devices are then reported to the user for future reference in the $ME file. The chosen device (whether default or selected) will be reported there as well.
Note
GPU based vortex wake implementation is designed to work on Nvidia graphics cards only and is tested and verified only for those.
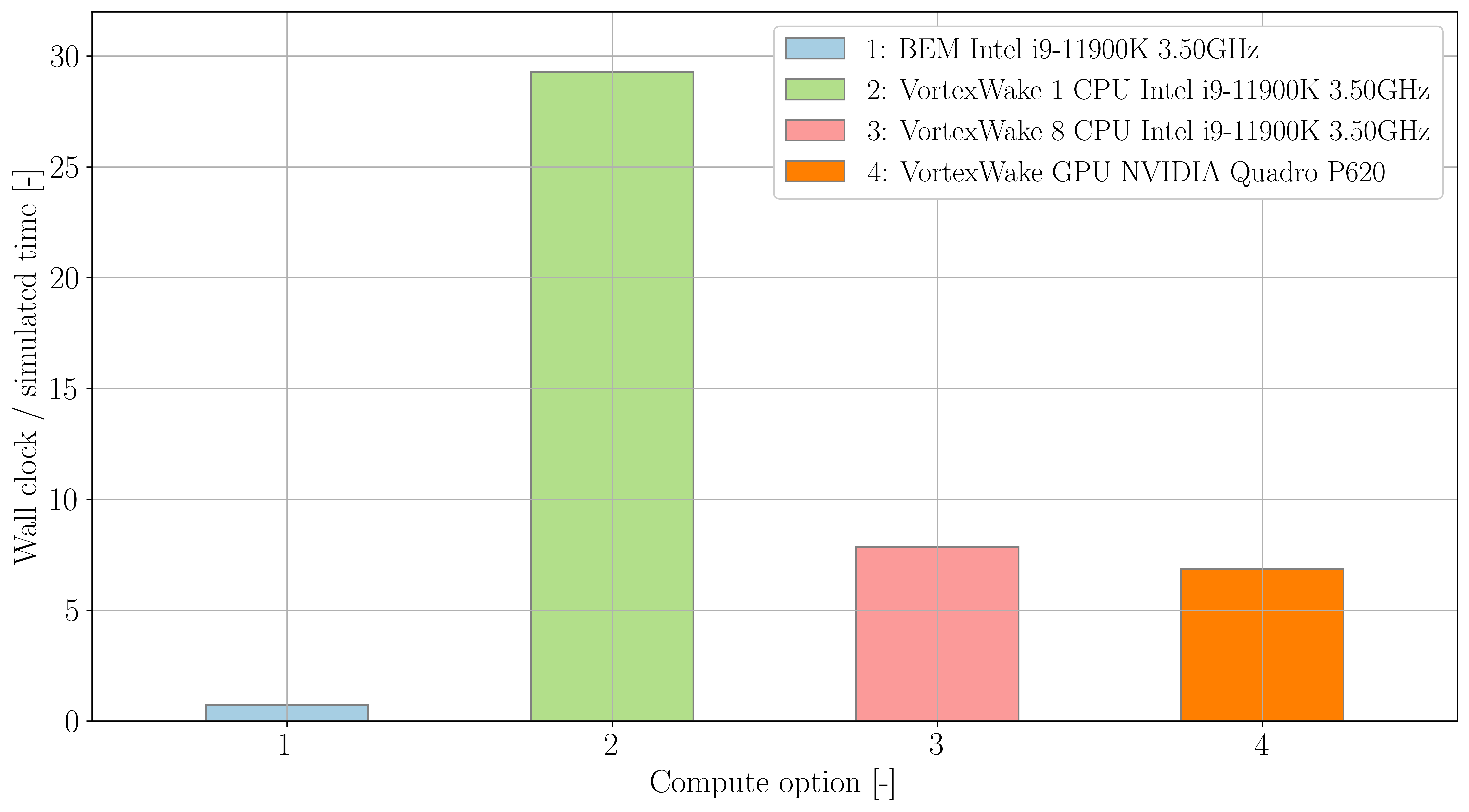
Comparison of computational efficiency
Figure 1 shows the relative performances of four different simulations. One uses the BEM method while the other three use the vortex wake with different performance enhancement methods and settings. The three cases considered are single-threaded CPU (no performance enhancement), multithreaded CPU and GPU. The BEM method runs in about real-time, faster than any vortex wake run. Note that the performance of the vortex wake method scales with the number of blade stations. Increasing the number of threads on vortex wake runs improves the CPU performance significantly, yet the GPU algorithm provides the best performance in this case.
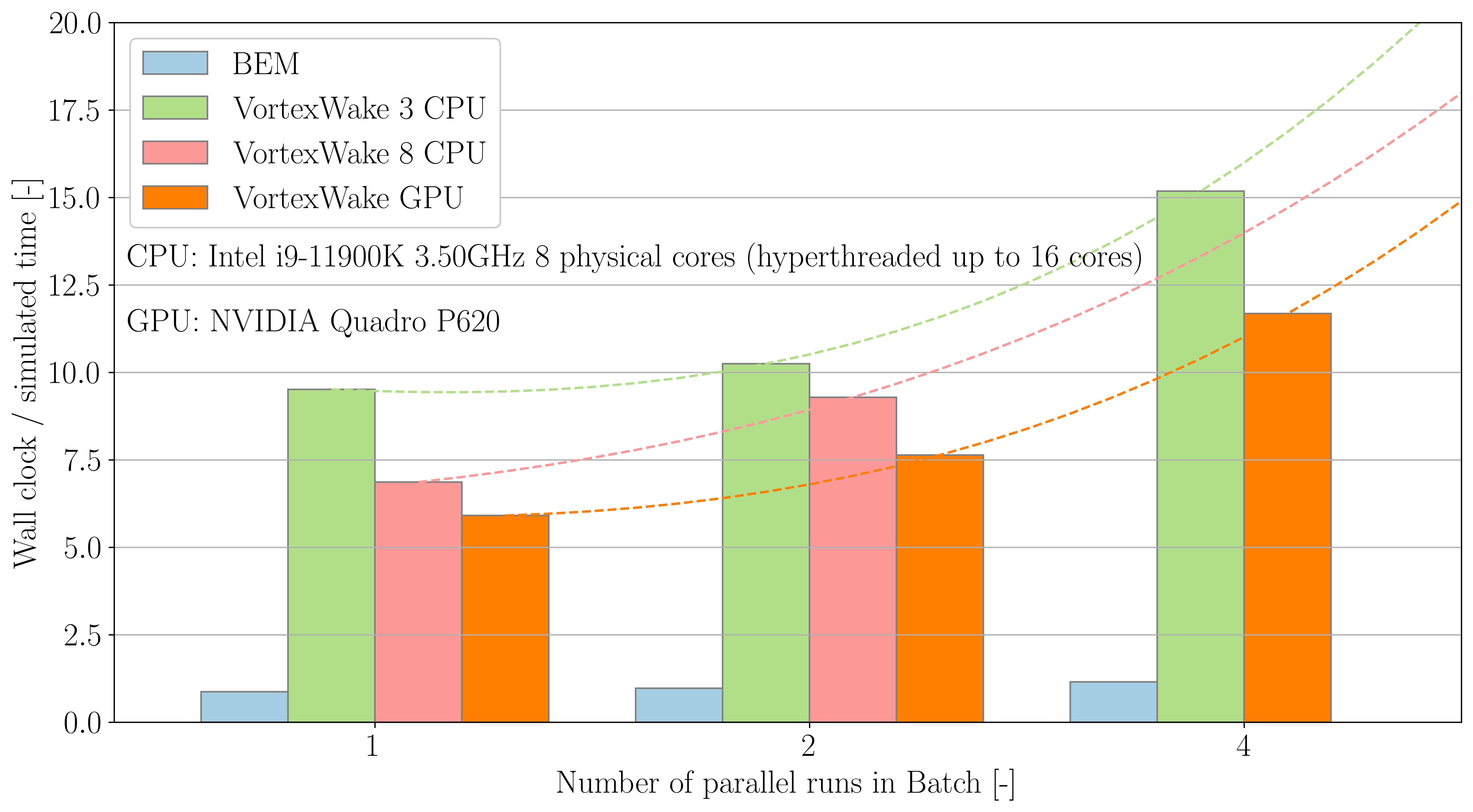
Figure 2 shows similar data based on the number of simultaneous runs using Batch. As the number of simulations increases the simulation time grows at an increasing rate because the hardware is required to switch between simulations. The overall time taken for these simulations is still lower compared to running them sequentially. If too many calculations are run in parallel the user may find there is no improvement to the overall time taken to complete a number of simulations relative to running the calculations in series.
Last updated 13-12-2024